Prophetの勉強のために、いろいろ分析ネタを探しているのですが、今日は変化点の抽出です。
テーマは、あいみょんやOfficial髭男dismがいつ頃からブレイクしたのか、Prophetの変化点抽出の機能で可視化したいと思います。
前半部分は、前回の記事と同じコードを使っています。
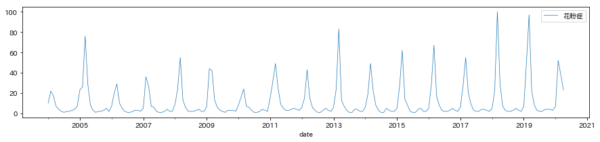
花粉症が増えているのか、ProphetでGoogleトレンドを分析した
まずはGoogleトレンドのデータを抽出
あいみょんとOfficial髭男dismを、Googleトレンドで検索した結果がこちらです。
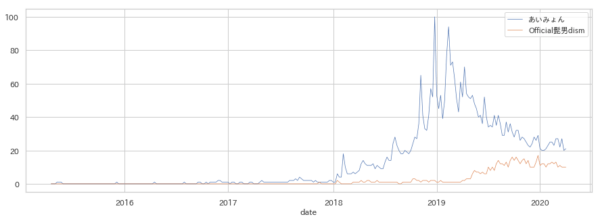
グラフでぱっと見た感じだと、あいみょんは2018年初め、Official髭男dismは2019年の半ばぐらいからでしょうか。
あいみょんを分析
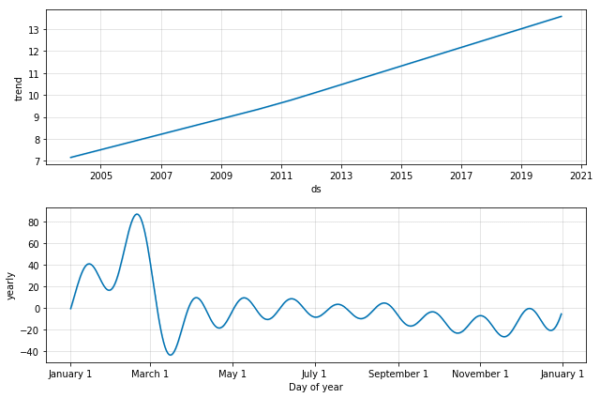
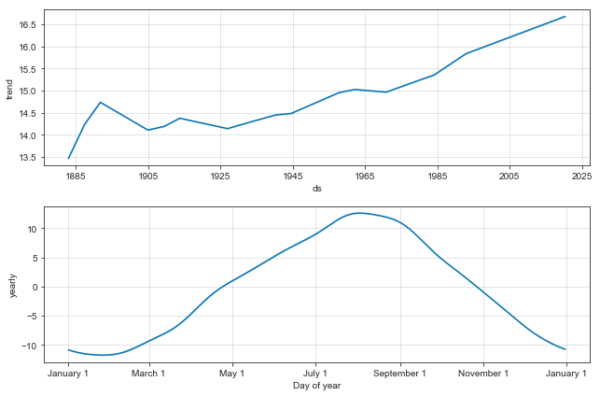
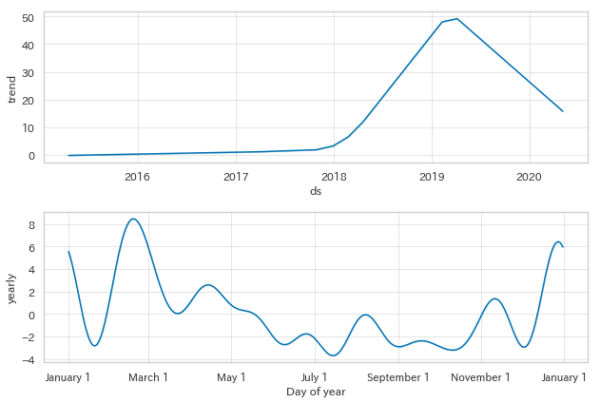
トレンドに分解すると、こんな感じです。ここで見ても、2018年で上がり始め、2019年を過ぎたころにピークを迎え、今は少し落ち着いてます。
で、今回のメインである変化点抽出。基本的には、こちらのサイトのコードを拝借しました。
Facebookの予測ライブラリProphetを用いたトレンド抽出と変化点検知 – Gunosyデータ分析ブログ
可視化したグラフとコードがこちらです。
[python]
import seaborn as sns
# add change rates to changepoints
df_changepoints = gt_data.loc[m.changepoints.index]
df_changepoints[‘delta’] = m.params[‘delta’].ravel()
# get changepoints
df_changepoints[‘ds’] = df_changepoints[‘ds’].astype(str)
df_changepoints[‘delta’] = df_changepoints[‘delta’].round(2)
df_selection = df_changepoints[df_changepoints[‘delta’] != 0]
date_changepoints = df_selection[‘ds’].astype(‘datetime64[ns]’).reset_index(drop=True)
# plot
sns.set(style=’whitegrid’)
ax = sns.factorplot(x=’ds’, y=’delta’, data=df_changepoints, kind=’bar’, color=’royalblue’, size=4, aspect=2)
ax.set_xticklabels(rotation=90)
[/python]
[python]
figure = m.plot(forecast)
for dt in date_changepoints:
plt.axvline(dt,ls=’–‘, lw=1)
plt.ylim(0,100)
plt.show()
[/python]
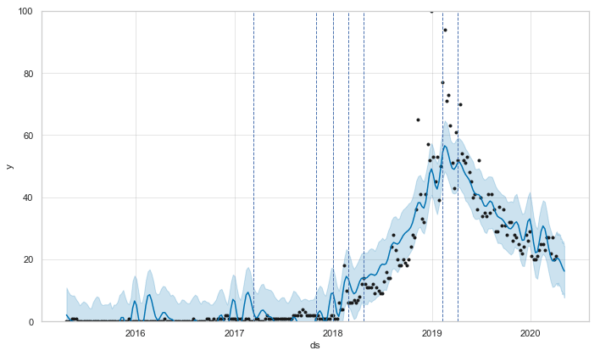
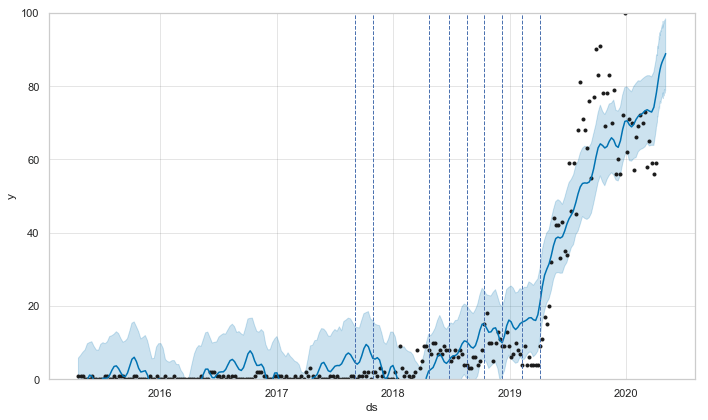
変化点はこんな感じになっています。
0 2017-03-12
1 2017-10-29
2 2017-12-31
3 2018-02-25
4 2018-04-22
5 2019-02-10
6 2019-04-07
グラフと照らし合わせながらみると、2017年10月~2018年4月ぐらいまでで連続して変化点が生じているので、このあたりがブレイクポイントかなと。
Wikipediaのディスコグラフィーと見比べると、「君はロックを聴かない」から「満月の夜なら」あたりでしょうか。
あいみょん – Wikipedia
Official髭男dismを分析
次はヒゲダンです。こちらは念のため、「Official髭男dism」と「ヒゲダン」の両方を見てみました。
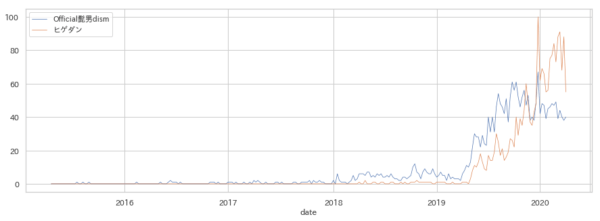
最近は「ヒゲダン」の方が多いんですね。ただ、ブレイク時期を見るには「Official髭男dism」の方がよさげなので、こちらで分析進めます。
あいみょんと同じように、まずはトレンドの分解から。
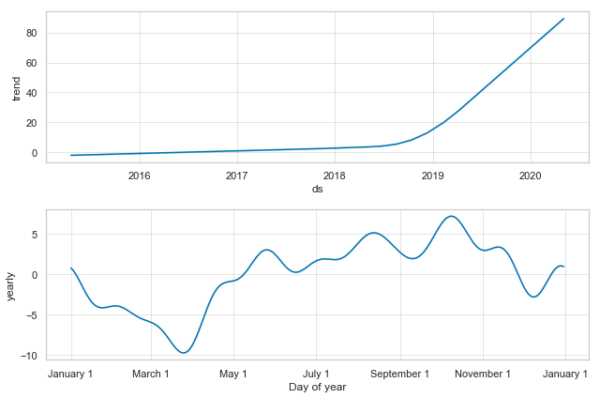
大きな変化点は、2018年の後半あたりにある気がしますね。
次は変化点抽出です。同じグラフはこちら。
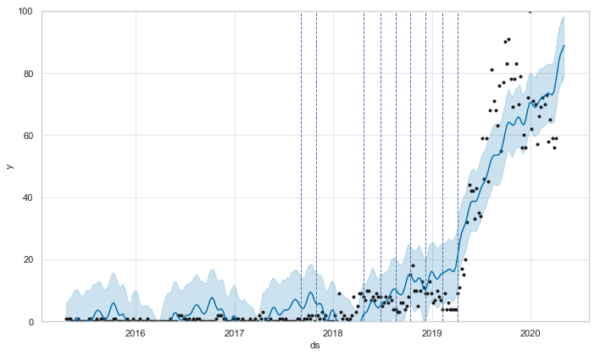
変化点はこんな感じになっています。
0 2017-09-03
1 2017-10-29
2 2018-04-22
3 2018-06-24
4 2018-08-19
5 2018-10-14
6 2018-12-09
7 2019-02-10
8 2019-04-07
こうみると、2018年過ぎたころから立て続けに変化点が訪れており、その都度Googleトレンドの値が徐々に上がっているのがわかります。最後、ガッと上がっているのが2019年4月ですね。
同じようにディスコグラフィーを見ると、メジャーデビューしたのが2018年4月なので、そのあたりがちょうどGoogleトレンドの上昇傾向の開始と合致します。そして、Pretenderの発売が2019年5月なので、この発売と合わせて急上昇していったように見えます。
Official髭男dism – Wikipedia
ということで、Prophetで変化点抽出を見てみました。目視でグラフで見るだけでは感じなかった、トレンドの変化を抽出することができました。逆に、違和感みたいなところもあるので、使い方次第というか、実データや背景などと組み合わせて読み解く必要もありそうです。